
Building Task-Independent Embeddings as a Service
The realm of applied Machine Learning (ML) has seen personalization taking the lead, with 45.1% of respondents in The State of Applied Machine Learning 2023 report highlighting its importance. While this may not represent all ML teams, it underscores the significance of recommender systems in driving business impact. User interactions with applications generate substantial data, providing implicit clues about interests and intentions. Leveraging this sequential information for personalization is a burgeoning area in recent research. This article explores the construction of task-independent user embeddings, their applications, challenges, and quality assessment methods.
Disclaimer: The content of this article reflects theoretical considerations in recommender systems and does not disclose any specific details related to past projects or organizations I was associated with. The opinions herein are my own and do not represent the views of any past employers.
Building Task-Independent User Embeddings
User-generated sequential logs present opportunities to create self-supervised models in terms of sequence reconstruction to apply later to a variety of tasks like marketing, user profiling, and recommender systems. Such representations can be vital when data sharing is complex across different verticals within an organization. Examples could be a superapp like Grab, where you have ride-hailing, food delivery, and groceries, or retail conglomerates, where you have supermarkets, fashion brands, online e-commerce, etc.
Embeddings are learnable representations of data that catch latent features and allow us to put, let’s say, users and items in one vector space and do math operations on them, like finding the closest pairs by cosine similarity or dot product. Plugging in User/Items Embeddings as an additional feature to individual teams models can give a great start and improve the quality without putting much effort into feature engineering. It also reduces silos and working on similar things in different departments. It solves the problem of data availability when you would like to include additional features in production, but making it available offline and online is a consuming task. It also allows us to keep low latency by using lighter real-time models on top of embeddings.
Here is an example of how an architecture of task-independent embeddings could look like in an abstract application:
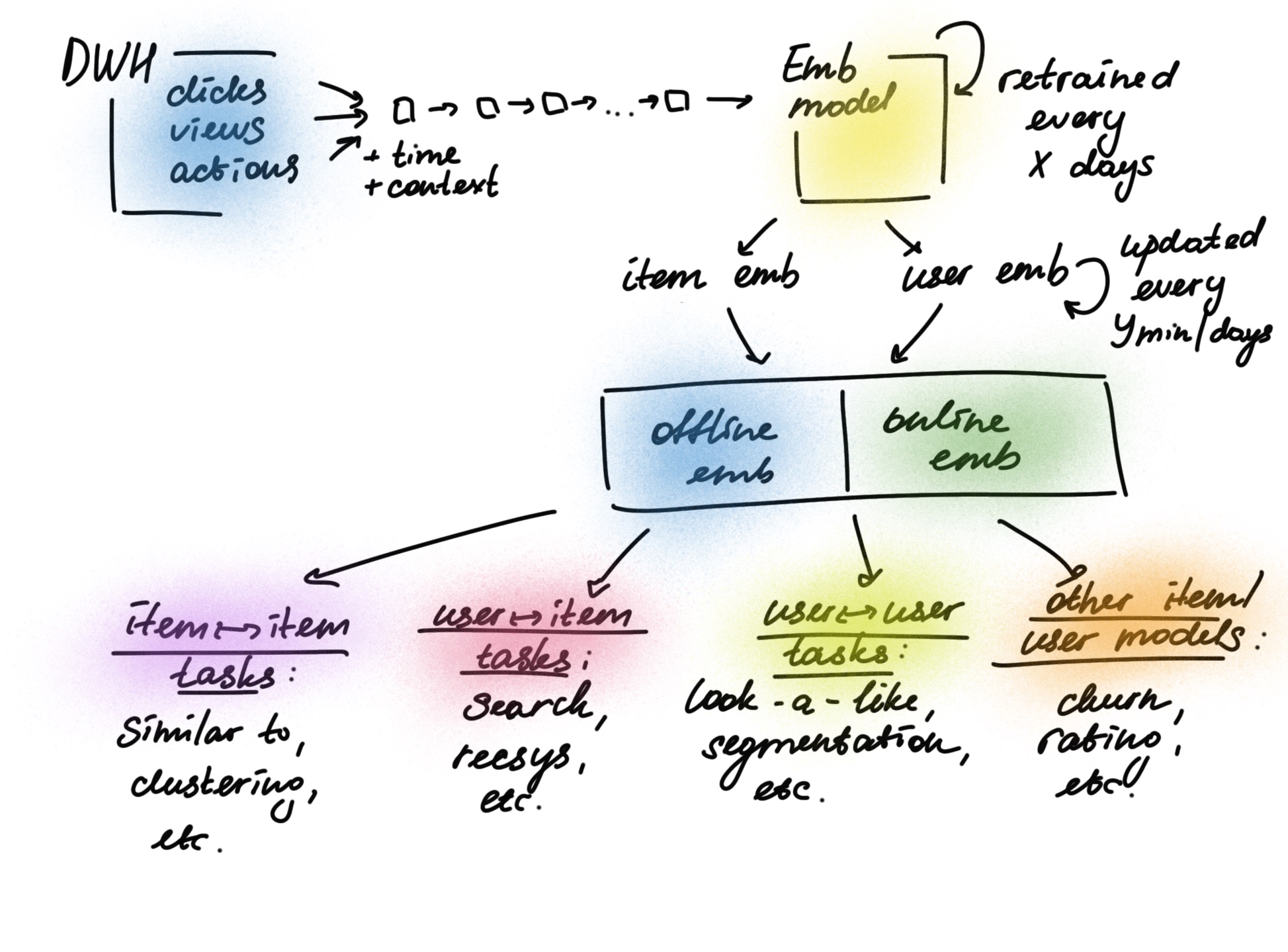
Leveraging Transformers for Sequential Recommendations
Much of the recent progress in sequential and session-based recommendation has been driven by improvements in model architecture and pretraining techniques originating in the field of Natural Language Processing (NLP), Transformer architectures in particular. In personalization, these models can be used to learn from sequential user behavior and predict future actions or preferences. However, user trails have some essential differences from NLP: the sequences are usually shorter than in NLP, they include additional side information like time aspect and the context of sequence activity, plus we need to use ranking metrics for evaluation.
One way to build such representations is to use the library Transofrmers4Rec by Nvidia based upon open-source HuggingFace. It is designed for research and production, includes time and context features, and integrates with PyTorch and TensorFlow.
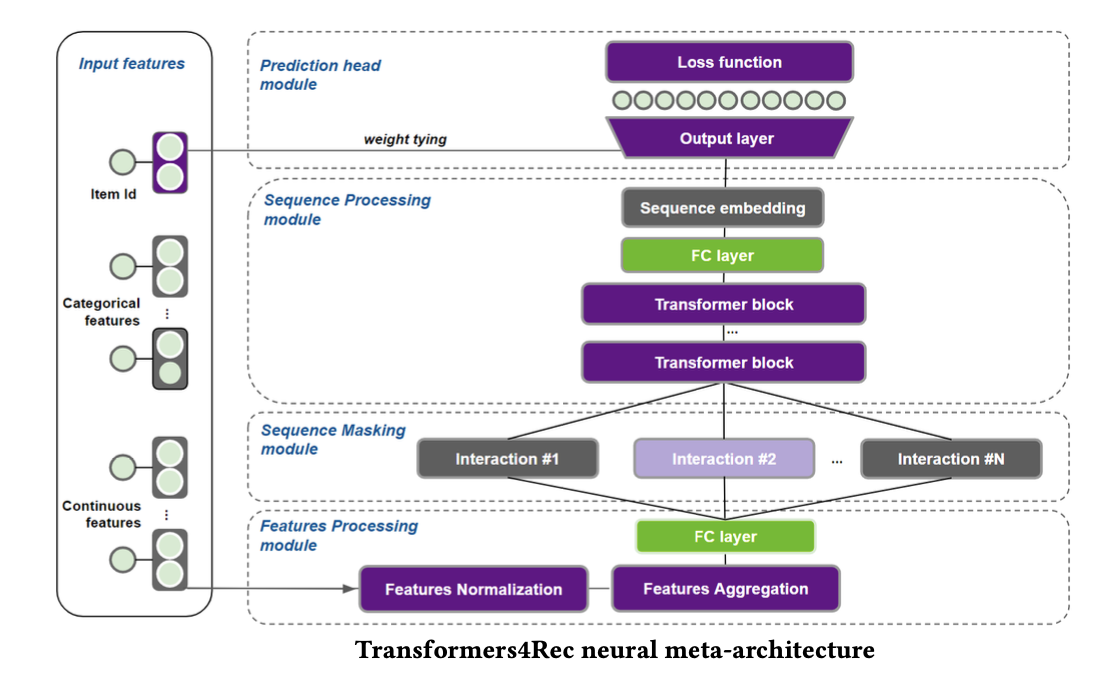
To create comparable embeddings for both users and items, you can train a model using the NextItemPredictionTask with the weight-tying technique, which connects the input item embeddings with the model’s outputs. As a result, both the user sequence representation and the item embeddings are constructed within the same vector space, making them compatible with one another.
Challenges
- Cold-start problem. The solution is to use averages of other embedding vectors with similar attributes, like the user’s location or item categories. Also, to learn embeddings for unpopular items, we can replace them with one item and later use it as a vector for items without enough history.
- Change of preferences. Periodic retraining and monitoring may help.
- Resources. It requires significant data and computational resources, so it can be batched calculated, and used by lighter models.
- Model Drift. Versioning and continuous metric monitoring are crucial.
- Interpretability. Attention heatmaps and feature importance analysis can enhance understanding.
How to estimate the quality?
- Use multiple tasks to validate the embeddings. If the embeddings are indeed task-independent, they should perform well across different predictive tasks within the organization. It’s a good idea to start with an offline evaluation.
- Embedding Visualization. Using techniques like t-SNE or PCA to reduce the dimensionality of the embeddings and visually assess whether they capture meaningful patterns.
- Cosine Similarity and Nearest Neighbors. Analyze the cosine similarity between embeddings to ensure similar users have similar embeddings. You can also compare distances between objects of different clusters.
- Regular monitoring and feedback loops with various stakeholders will ensure continuous alignment and quality control.
Conclusion
The deployment of task-independent user embeddings offers myriad applications while posing several challenges. Leveraging libraries like Transformers4Rec bridges the gap between NLP and recommendation, creating new pathways for personalization and task-agnostic modeling.
Further Reading:
- Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation
- Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation
- Listing Embeddings in Search Ranking by AirBnB
- A Practical Guide to Building an Online Recommendation System
- Scaling the Instagram Explore recommendations system
- Innovative Recommendation Applications Using Two Tower Embeddings at Uber